[Update 2021: you can now figure out the cost of versioning using S3 Storage Lens]
We all love versioning on Amazon s3. It gives us peace of mind and the ability to recover our data if something goes wrong. As for the Amazon documentation:
Versioning is a means of keeping multiple variants of an object in the same bucket. You can use versioning to preserve, retrieve, and restore every version of every object stored in your Amazon S3 bucket. With versioning, you can easily recover from both unintended user actions and application failures.

But what about costs?
Keeping many variants of an object will not be free. And as for S3 FAQ, the billing for once is obvious:
How am I charged for using Versioning?
Normal Amazon S3 rates apply for every version of an object stored or requested
Versioning has a simple price structure but how do you monitor the impact on your storage costs? If you spend 10K every month on S3, it is useful to know if versioning is 5%, 10% or 20% of the bill.
Knowing that normal rates apply for every version of an object does not answer the questions:
- what percentage of your storage is used by versioning?
- how much enabling versioning is costing you at the end of the month?
If you have 100s of TB or PB of data, millions or billions of objects, you cannot list the bucket and check the items one by one. It would be anyway too costly to do that. There is no direct way to find the added cost of the versioned objects using Cost Explorer. And the Cost and Usage Report provides only the total cost of your bucket.

What about CloudWatch?
A metric in CloudWatch would be the perfect solution, as it would be easy to track and monitor. Unfortunately there is no metric that covers versioning. The current metrics available for a S3 bucket refer only to the number of objects or to the different storage classes, for example:
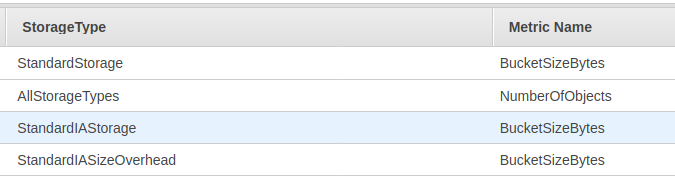
CloudWatch could only help if we knew upfront the ratio between current and previous versions.
What about using the AWS CLI?
You can do almost everything using the AWS CLI. Including listing all the objects in your bucket and figure out their size and versioning status. A very dummy command could be:
$ aws s3 ls s3://YourBucketName --summarize --human-readable –recursive
The output can be processed and the compared with the total size from the CloudWatch metric to get the estimate of the total version size.
Unfortunately, the approach does not scale when you have a large bucket. Besides, listing periodically all the objects has its own costs and you might end up paying more than what you spend in versioning.
S3 Inventory then!
A not immediate but very accurate way to determine the cost of versioning is using S3 Inventory. What is it?
Amazon S3 inventory provides comma-separated values (CSV), Apache optimized row columnar (ORC) or Apache Parquet (Parquet) output files that list your objects and their corresponding metadata on a daily or weekly basis for an S3 bucket or a shared prefix (that is, objects that have names that begin with a common string).
We can generate two inventory reports in which the first report includes all versions of object and the second includes only the current versions. After calculating the size from both the reports, subtract the current version objects size from all version objects size.
But even easier, we can generate a single inventory report including only the current versions, compute the storage and compare it to the total bucket size from CloudWatch.
Sampling?
If you have a well distributed bucket, you can analyze only a meaningful subset of your data. It would be faster and cheaper too. For example, if the prefix of all your objects is randomly distributed between aa and zz, you can use a subset of objects using S3 Inventory or AWS CLI to estimate your costs.
For example, out of the 676 prefixes (26 × 26) below you can sample just a handful of them.

What about Cost Explorer?
We said that Cost Explorer does not expose the cost of versioning. But it can be used as a proxy, if you have a lifecycle rule in place to permanently delete previous versions .
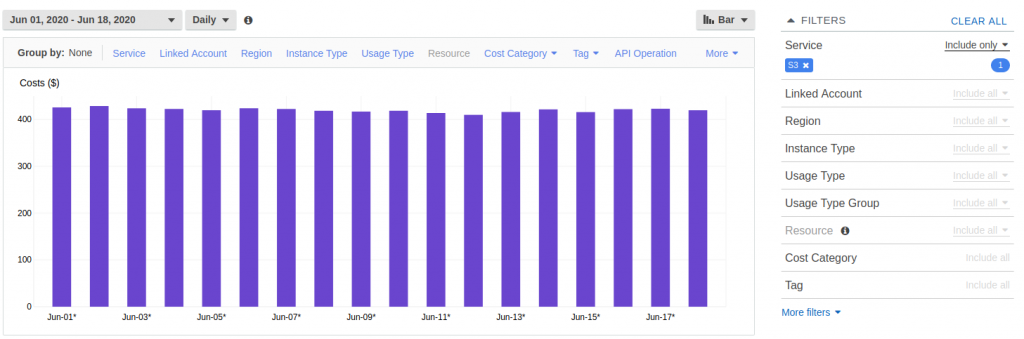
Let us assume you have a retention of 30 days for previous versions. You can temporarily increase it and use the daily view of S3 costs in Cost Explorer to see if and how much it affects your billing. For example, you can increase the retention to 40 days, wait 10 days and rollback the change to 30 days.
If the cost of your versioning is significant, you will an increase for those 10 days with a drop when you rollback the change. If not, you know that the percentage of costs of versioning in your S3 bill is not significant, as in the following example.
To recap…
There is no simple way to determine the percentage cost of using versioning on S3 but there are a few options to have a reliable estimate. Use S3 inventory for an accurate value, play with a sample of your data or change a lifecycle rule for a reasonable guess.