Thank you #alldaydevops for having me today. It was a pleasure discussing the advantages of serverless databases and playing with Aurora Serverless v2. And I still do not understand why the tax accountant questions an ironing board as an essential item for a software engineer.



Now it is the time to listen to some great free talks on ADDO, still many sessions to go until tomorrow at 9 AM CET. The abstract of my presentation is below.
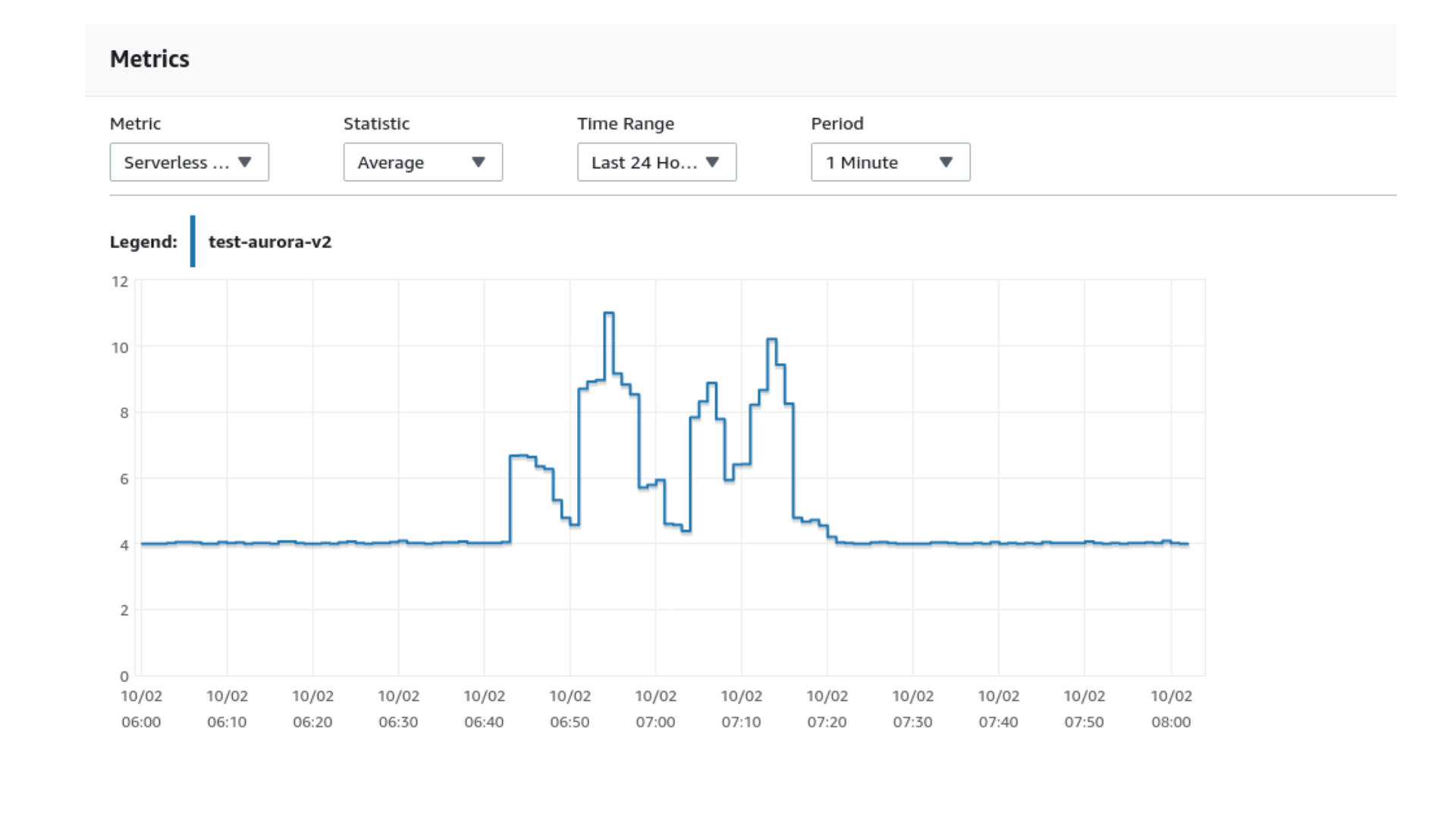
Drawing the NYC Skyline with a serverless database

Serverless databases are a challenging area for cloud deployments, with providers trying to extend the elasticity of managed solutions to RDBMS databases. If the new options are so elastic, with CPU and database capacity strictly correlated, can we perform some creative benchmarking using a serverless database?
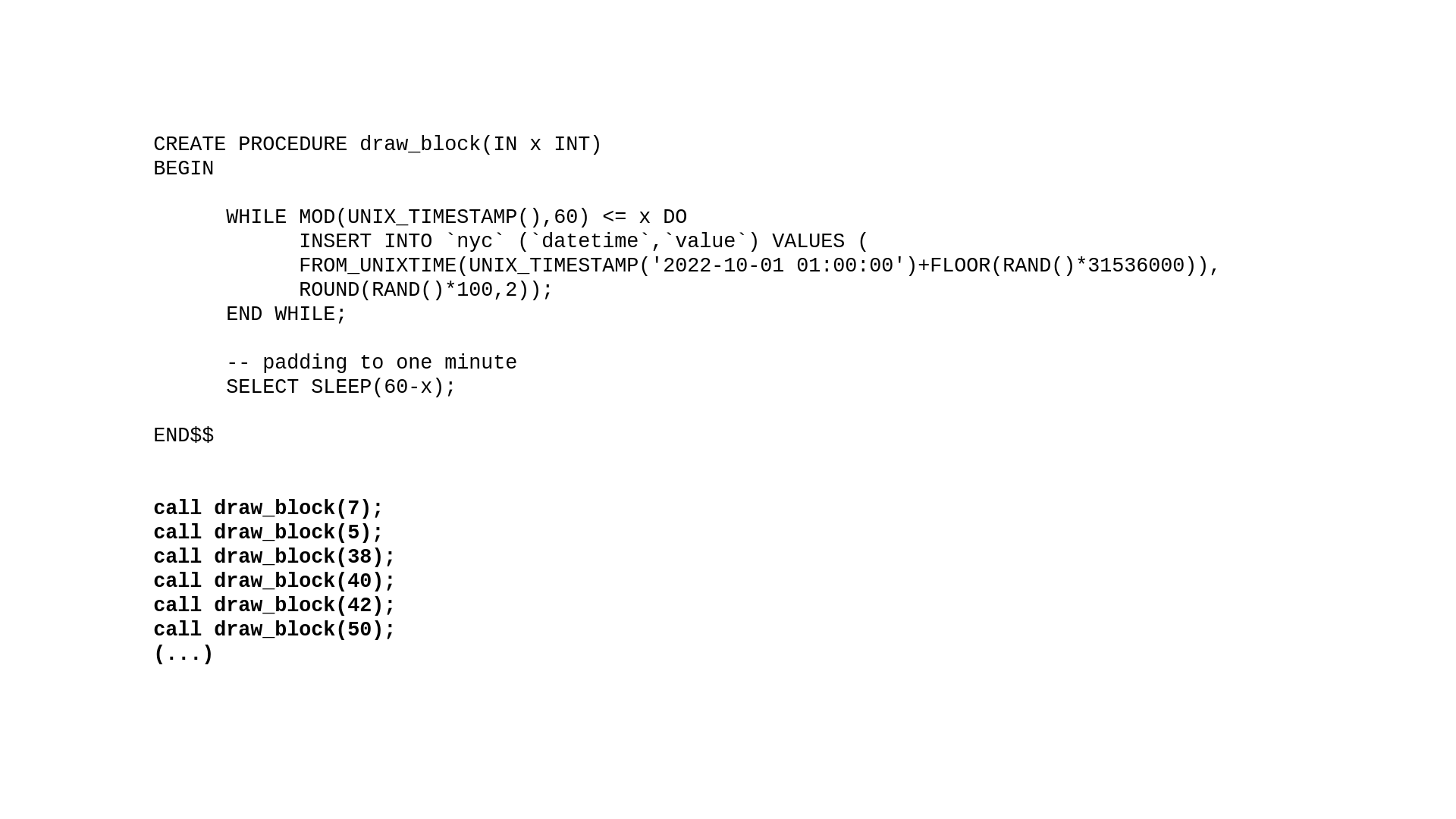
In this session, we will discuss database elasticity and serverless databases, seeing how they can adapt the capacity vertically and incrementally according to the load and the resources consumed. Ignoring standard load testing tools and simulation models, we will perform different tests with simple SQL statements. If Aurora Serverless v2 is elastic and can scale quickly, is it possible to create a load where the database capacity plots the NYC skyline in Amazon CloudWatch?