Today, we’ll embark on a little journey around the world using S3. We’ll copy various objects across AWS regions worldwide, aiming to answer two simple questions:
- Does the storage class affect the speed?
- How does the size of the object influence the transfer time?
Verne’s Journey
Imagine wagering your entire fortune on a wild, globe-trotting adventure. That’s exactly what Phileas Fogg, a meticulous and mysterious Englishman, does in Jules Verne’s Around the World in 80 Days, racing against time and overcoming a few unexpected obstacles.
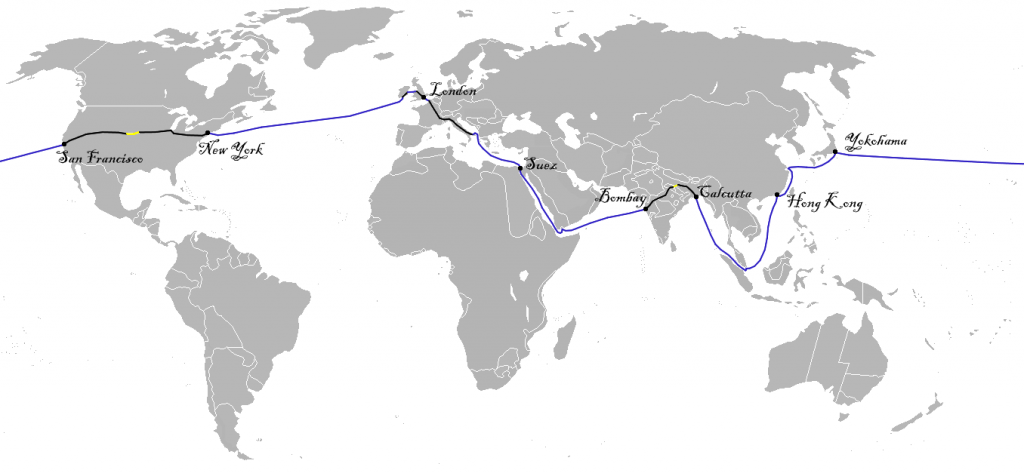
While Fogg sets out to prove he can circumnavigate the planet in just 80 days, we want to prove we can circle the globe through AWS data centers in just a few seconds—copying S3 objects worldwide in the fastest way possible. Fogg begins in London, traveling through Europe, Asia, the United States, and back to Ireland before returning to London. Can we achieve something similar with Amazon S3? AWS doesn’t (yet) have 80 regions, but we don’t need them. Instead of using all the available regions, we’ll stick to fifteen, just enough to follow Fogg’s route.
Ruling Out S3 Replication
First off, do we need to implement the logic ourselves? Can’t we just use S3 replication? As a lazy cloud architect, that would definitely be my favorite approach. It’s the first thing I’d consider to send my objects worldwide in 80 buckets.
However, replication does not work on cascade and it is an asynchronous operation that can take up to 24–48 hours. You can reduce the replication time to an SLA of 15 minutes by paying a bit more—but even that’s still not the fastest way to move objects globally. I want to be as fast as possible when moving my data, so I’ve decided to implement this journey myself.
A Simple S3 Setup
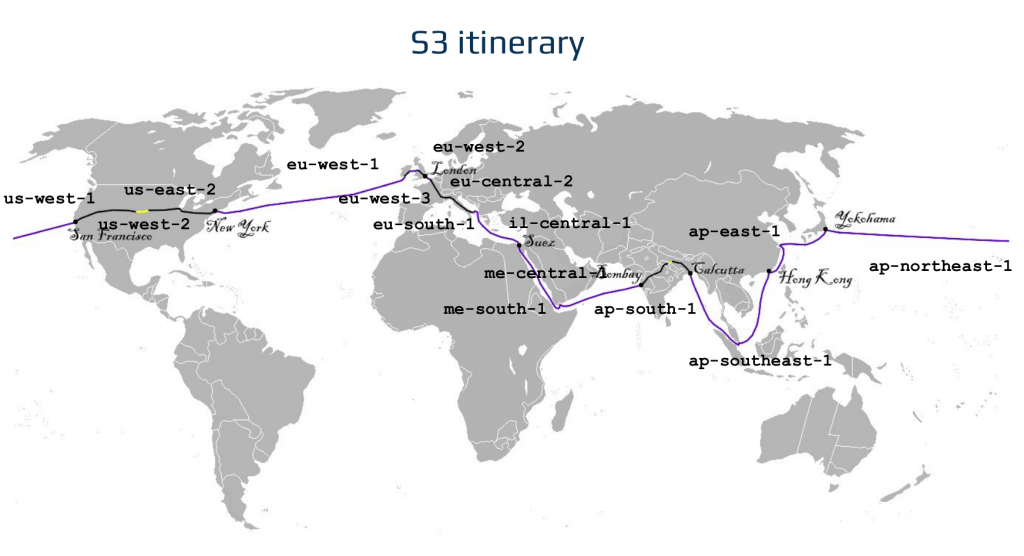
First, we need a bucket in every region we plan to use. Here’s the list of regions for our experiment.
verne_buckets=("eu-west-2" "eu-west-3" "eu-south-1" "il-central-1" "me-south-1" "me-central-1" "ap-south-1" "ap-southeast-1" "ap-east-1" "ap-northeast-1" "us-west-1" "us-west-2" "us-east-2" "eu-west-1" "eu-west-2")It’s just a subset—we could add a few more (like Northern Virginia), but doing so wouldn’t significantly affect the results. If you want to replicate this experiment yourself, keep in mind that some newer regions aren’t enabled by default, so you’ll need to take care of that first.
Another hurdle is that you can’t use the same bucket name in different regions, which means all our bucket names need to be unique. How can we manage that? The simplest—though not the most elegant—approach is to create a reasonably unique prefix and append the region code to the name. For example verne-demo-us-east-1. Once we have an array of the regions we’re using, we can use the AWS CLI to create those buckets.
s3prefix="verne-demo"
for region in "${verne_buckets[@]}"
do
bucket_name="$s3prefix-$region"
echo "aws s3api create-bucket --bucket $bucket_name --region $region --create-bucket-configuration LocationConstraint=$region"
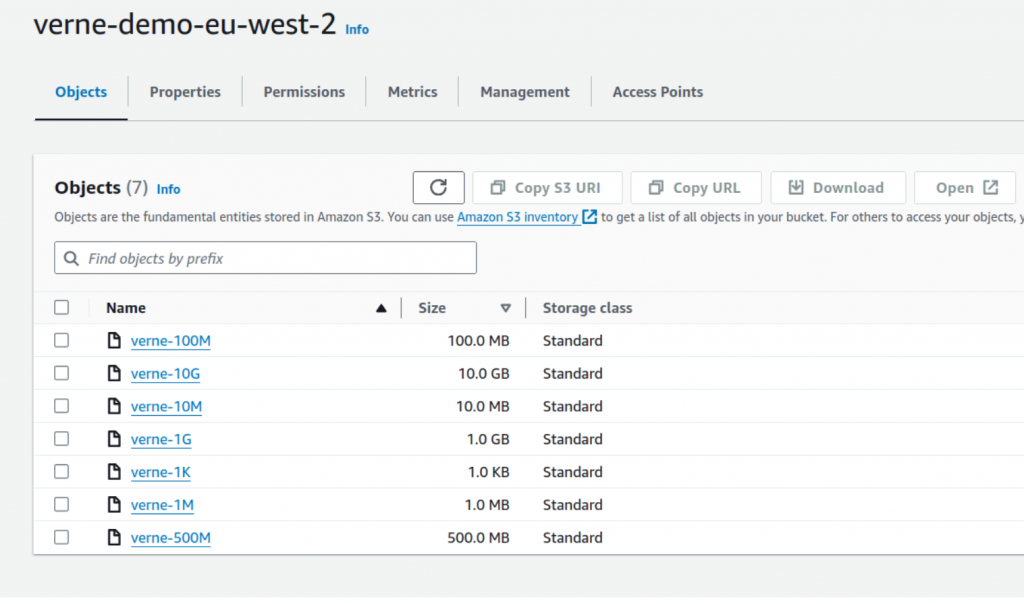
doneWe can then upload files of different sizes to our very first region, London—the city where Verne’s journey begins, and so does ours. In theory, we could upload objects up to 5TB (the maximum size of an object on Amazon S3). However, to keep the test simple—and the storage and transfer costs negligible—we’ll stick to the following items and sizes.
How can we now copy data between buckets around the world? The most obvious and elegant way is to go serverless, using AWS Lambda and Amazon S3 event notifications. When an object lands in a bucket, you can trigger a Lambda function to copy it to another bucket, and so on.
But I’m a lazy developer, and I just need to answer a few simple questions. I don’t want to deploy Lambda functions everywhere and deal with a lot of setup. Thankfully, with the AWS CLI and AWS CloudShell, the task is straightforward and the overhead minimal. When you copy an object between two regions using the CLI, the binary doesn’t pass through your terminal—it’s handled directly between AWS data centers.
for (( i=0; i<$array_length-1; i++ ))
do
aws s3api copy-object --copy-source $s3prefix-${verne_buckets[$i]}/$objectname --key $objectname --bucket $s3prefix-${verne_buckets[$((i+1))]} --region ${verne_buckets[$((i+1))]} --storage-class $testclass
doneOn Our Way
Let’s run our simple tests. You’ll immediately notice that using the S3 copy-object operation makes our journey impressively fast. You can circle the globe in just 23 seconds! However, as the object size increases, transfer times start to scale linearly. For example, compare the times for 100 MB versus 500 MB. At smaller sizes, the overhead of the commands becomes more noticeable.
| s3api copy-object | s3 cp (multipart) | |
| verne-1K | 23s | |
| verne-1M | 31s | |
| verne-10M | 56s | |
| verne-100M | 5m25s | 3m40s |
| verne-500M | 25m42s | 5m27s |
What happens when you switch to the multipart scenario? The growth is no longer linear, and it’s impressive that you can copy a 500 MB object across 15 buckets in about 5 minutes using the default client configuration. No tuning of the S3 client configuration was performed.
| storage class | s3api copy-object 1M |
| STANDARD | 30.4s |
| STANDARD-IA | 31.0s |
| ONEZONE-IA (*) | 31.2s |
| GLACIER-IR | 30.9s |
| REDUCED_REDUNDANCY (*) | 29.6s |
With multiple storage classes available, does the storage class matter? Two storage classes—the deprecated S3 Reduced Redundancy and S3 One Zone-Infrequent Access—don’t use three separate AZs. Would that offer any speed advantage? The short answer is no. All storage classes that provide immediate access to the object, including Glacier Instant Retrieval, behave similarly.
Conclusions
This isn’t a benchmark or even a proper test. It’s just a fun experiment to validate some ideas about Amazon S3: the storage class of your objects doesn’t affect the time needed to copy them across regions, and the transfer time grows linearly with the object size—unless you use multipart upload.
Also, Amazon S3 and AWS networks are impressively fast.