As a cloud architect and storage expert, I often hear the question: Which storage class should I use on Amazon S3? The answer is simple: as always, it depends. Today, we’ll explore some anti-patterns you might overlook when transitioning data between storage classes, whether using lifecycle rules or a managed class like S3 Intelligent-Tiering.
A Short Journey Back in Time
Amazon S3 was announced almost 19 years ago. It’s one of the oldest services on the platform, second only to Amazon SQS. What we see today as Amazon S3 vastly differs from what was available many years ago.
Even just a few years ago, there was no S3 Storage Lens, no conditional writes (introduced earlier this year), and no S3 Intelligent-Tiering storage class. There were no S3 triggers, there was no replication across buckets or regions. When I started working with S3 (around 2010), it was a fairly limited service but, in some ways, simpler than it is today.
At the same time, we tend to forget how expensive it was. As part of the announcement 19 years ago, Jeff Barr wrote:
“1 GB of data for 1 month costs just 15 cents.”
The same storage class today costs just 2.3 cents (or less) per GB in the US East region. With additional storage classes designed to optimize costs, it can go below 0.1 cents per GB.
| Standard | 2.3 cents (or less) |
| Standard Infrequent Access | 1.25 cents |
| Glacier Instant Retrieval | 0.4 cents |
| Glacier Deep Archive | Less than 0.1 cents |
AWS keeps iterating, adding new features and options. As a cloud architect, your job is to stay up to date. If you deployed and optimized costs on S3 five years ago, it’s time to revisit your setup. There’s a good chance your deployment is no longer optimized, and you might be leaving money on the table. Keep iterating!
How to Choose a Storage Class
Choosing the right storage class depends on the scenario, use case, and associated costs. The price isn’t just about storage. Costs also depend on how you access your data, how you upload it, and how you move it around. So, deciding on the best storage class isn’t always straightforward.
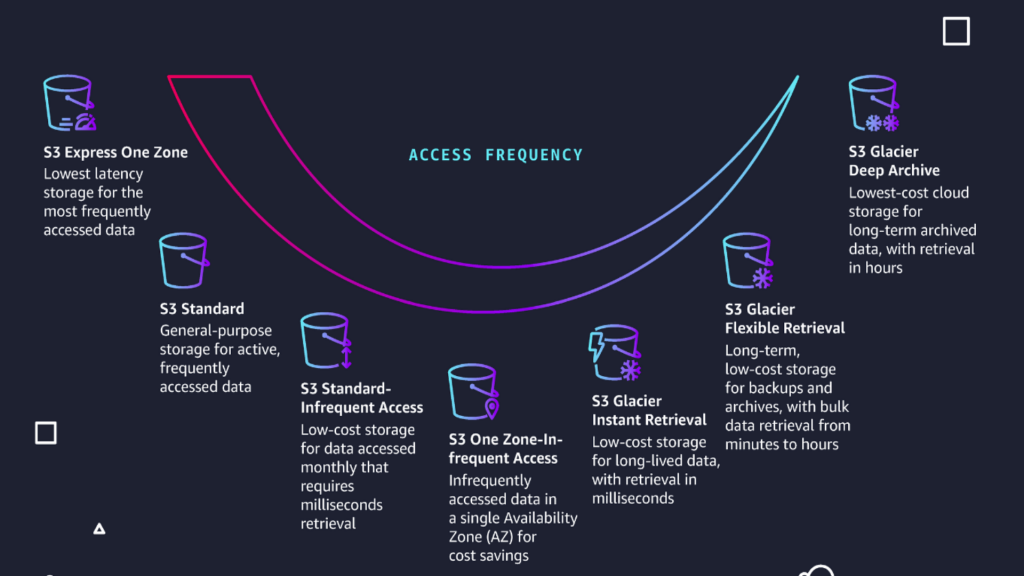
Hot storage refers to data that is frequently accessed and requires fast, consistent response times. On the other hand, cold storage is designed for data accessed infrequently and without the urgency required for hot data. The challenge? The same data often transitions from hot to cold over time.
Different classes come with varying retrieval costs, latency, availability, and minimum time commitments. Some classes store every copy of the data in a single Availability Zone, while others replicate data across three different ones. Different requirements mean different use cases. So, the big question is: how do you choose your storage class?
There are some common patterns. Typically, new data is “warmer.” Over time, the likelihood of accessing that data decreases. This isn’t unique to AWS or object storage. For example, Dropbox has shown that even in backup solutions, most retrieved data is newly uploaded:
“As we have observed that 90% of retrievals are for data uploaded in the last year and 80% of retrievals happen within the first 100 days”
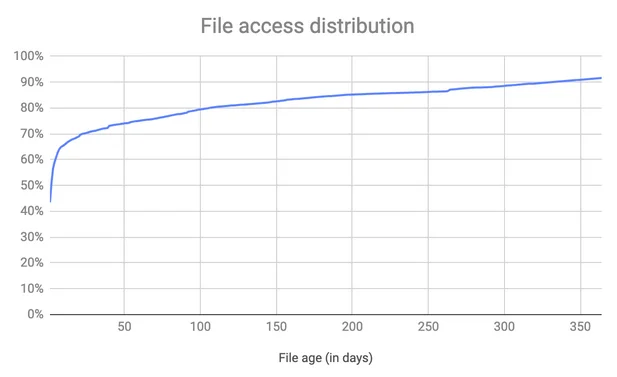
Ideally, you want recent data in hotter storage classes and older data in colder ones.
Lifecycle Rules Help
How can you move data across storage classes? On S3, the easiest way is with S3 Lifecycle. These rules are incredibly powerful—you can decide which storage class to use, the size of objects to move, and when to move them. For example, I can move my data to a cheaper storage class after 45 days because I know I will not need to access it anymore. I can also specify that only large files are moved to colder storage classes, while smaller files (like thumbnails) stay in the Standard class to avoid a higher chance of retrieval fees.
Why do I focus on size? Object size matters for lifecycle rules and, as we will see shortly, for S3 Intelligent-Tiering as well. You pay for operations (transitions) by the number of objects, while storage is charged by size. What does that mean in practice? Let’s break it down with a simple example.
Imagine I have 1 PB of data to move from Standard Infrequent Access (Standard-IA) to Glacier Instant Retrieval (Glacier-IR). How much does the transition cost? How does it impact my overall S3 costs? And how long does it take to recoup my transition expenses?
| 1GB size objects | 1MB size objects | 200KB size objects | |
| Transition to GIR: | 1M | 1000M | 5000M |
| Cost of transitions (one off): | 20 USD | 20000 USD | 100000 USD |
| Storage saving (monthly): | 17000 USD | 17000 USD | 17000 USD |
| Recoup time: | < 1 day | 1+ month | 6 months |
If my 1 PB consists of 1 GB objects, I’ll pay about $20 for the transition, while monthly storage costs would be approximately $17000. However, as object sizes decrease, transition costs become less trivial. You might still choose to move the data, but it’s important to understand your upfront costs.
The best way to estimate these costs is to use S3 Storage Lens. Ideally, you want most small objects in the Standard class and larger objects in colder classes. Below is an example of a distribution for an almost 20 PB bucket.
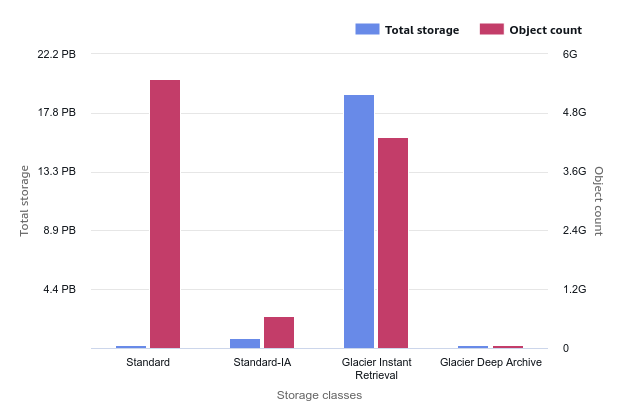
A more detailed example was shared by Canva last year on the AWS Storage Blog: How Canva saves over $3 million annually in Amazon S3 costs
What about S3 Intelligent-Tiering?
Why develop your logic when Amazon provides a managed class that handles this for you, without charging transition or retrieval fees? S3 Intelligent-Tiering is indeed the ideal choice for most use cases and the default choice for many workloads.
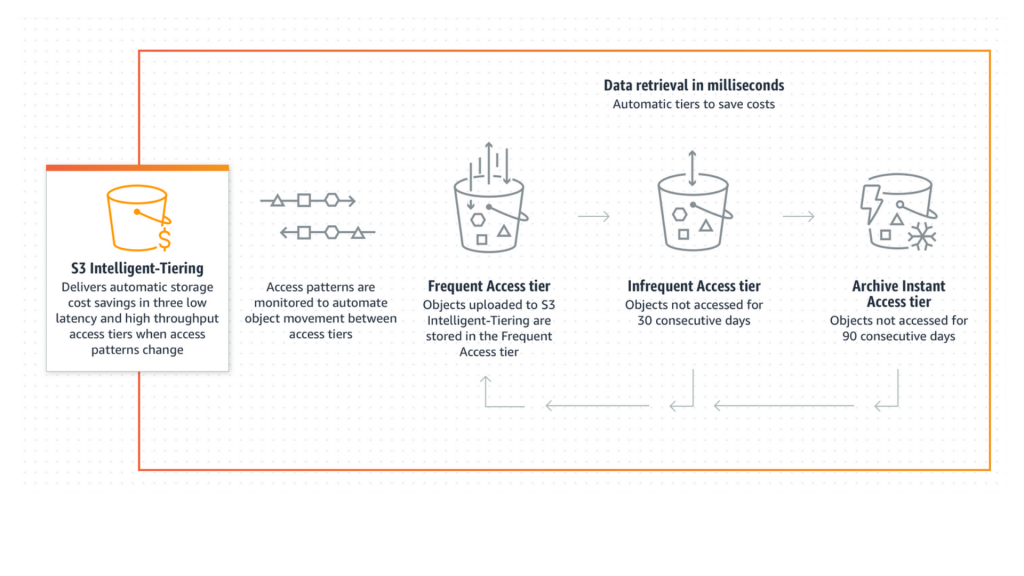
However, it’s still important to understand how the S3 Intelligent-Tiering class works under the hood and why object size remains a key factor. Let’s start with the AWS documentation:
“For a small monthly object monitoring and automation charge S3 Intelligent-Tiering moves objects that have not been accessed for 30 consecutive days to the Infrequent Access tier for savings of 40%; and after 90 days of no access they’re moved to the Archive Instant Access tier with savings of 68%. If the objects are accessed later S3 Intelligent-Tiering moves the objects back to the Frequent Access tier.”
The bold emphasis is mine. Now, how much is the “small monthly object monitoring and automation charge”? What are the implications of moving objects back? Let’s revisit the example of 1 PB of data. How much would this small management fee cost?
| 1GB objects | 1MB objects | 200KB objects |
| 1M | 1000M | 5000M |
| 2.5 USD | 2500 USD | 12500 USD |
Once more, the answers depend on the average size of your objects. The management fee might be negligible, or it might cost you more each month than the storage itself.
With S3 Intelligent-Tiering, there are no retrieval fees, but the object is moved back to the most expensive Frequent Access Tier (Standard class) for 30 days and then stays for another 60 days in the Infrequent Access tier. Retrieving one object means you’re not paying a retrieval fee, but you are paying more for the storage of the object for the next 90 days. How much is that extra overhead?
| 1GB objects | 1MB objects | 200K objects | |
| Intelligent-Tiering | 48.5 USD | 48.5 USD | 48.5 USD |
| GIR (once) | 30 USD | 30 USD | 30 USD |
| GIR (10x) | 300 USD | 300 USD | 300 USD |
Here, the key metric is the number of times you expect to retrieve that specific (colder) object after the first retrieval. Should you not use the managed storage class? Far from it. S3 Intelligent-Tiering is an amazing option, but—as with any managed service—it’s critical to understand the cost implications. Your retrieval patterns and the average storage size of your object matter.
Whenever you develop your logic with Lifecycle Rules or you delegate the logic to the S3 Intelligent-Tiering class, the average size of your objects on S3 is a significant factor in your storage costs. Move larger objects first; that’s where most of the storage saving lies.