Author: renato
-
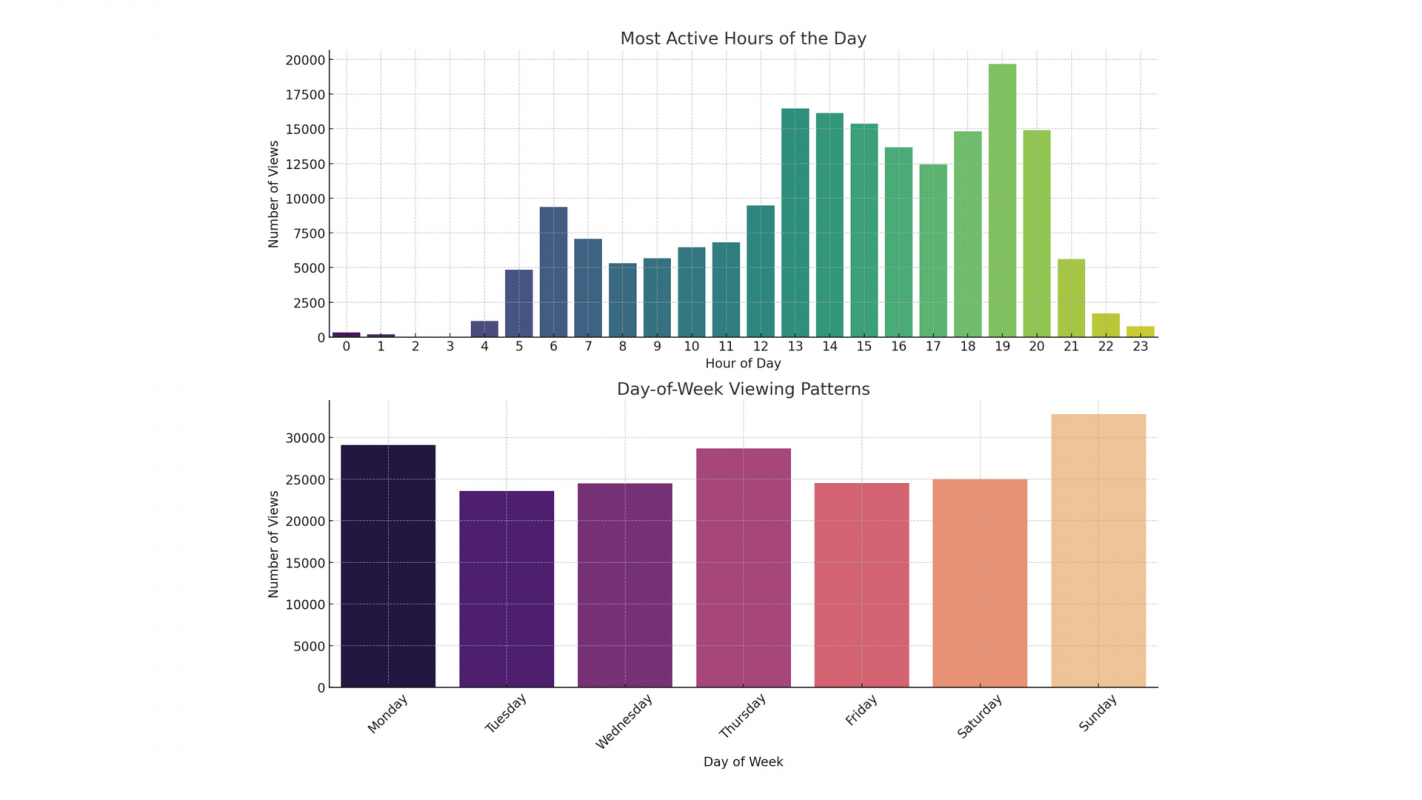
You Know What About Me? Decoding My Digital Trail Across Major Platforms
Under European rules, users can request personal data from platforms, but few do, and results are often hard to use. I accessed and parsed data from TikTok, Amazon, Google, and Instagram, uncovering surprising insights and useful tips. Find out what these platforms know about me. And maybe you too! Read the full article.
-

SREday Cologne 2025!
Just over one month to go until SREday Cologne. Slides ready, I am currently planning my short trip to one of my favorite cities in Germany to share some tips on running MySQL workloads on managed databases. As well as some mistakes I’ve made over the past decade that you can hopefully avoid. See you…
-

InfoQ – April 2025
From Firestore with MongoDB compatibility to Redis 8, from PlanetScale Vectors to Cloudflare Security Week, a recap of the news I wrote for InfoQ in April 2025. Read the full article.
-

Things Fall Apart: Navigating Managed Databases for Over a Decade as a Non-DBA
Learn to navigate database benchmarks wisely! From crashing managed instances to skyrocketing storage costs, I’ll share hard-earned lessons from a decade of managing production databases on the cloud without DBA expertise.Read the full article.
-

InfoQ – March 2025
Here are the articles I wrote for InfoQ in March 2025, covering everything from Fauna shutting down to the available European cloud providers. Read the full article.
-

Amazon S3 Around the World in 15 Buckets #DataPopkorn 2025
Let’s play a replication game on the cloud with Amazon S3. In this short talk, we will follow an S3 object on a 16-replication journey around the world, encountering surprising challenges, and learning one thing or two. Read the full article.
-

Data Popkorn 2025
Around the world with Amazon S3, in just a five-minute talk. See you soon online at Data Popkorn 2025!