Category: cloud
-

AWS Amarathon 2025
This morning, I have been presenting again at the 12-Hour Marathon Geek Talk, hosted by AWS User Group China.
-

SREday Amsterdam 2025
Just back from Amsterdam. I attended SREday 2025 with a talk on a mistake we all make sooner or later: Nobody Ever Got Fired for Implementing Multi-AZ.
-

Serverless Architecture Con Berlin 2025
Back in Berlin for Serverless Architecture Con 2025 with a talk close to my heart:
-

re:publica Hamburg x Reeperbahn Festival 2025
Session: What They Know: Decoding My Digital Trail Across Major Platforms.
-

Platform Engineering Patterns for Scalable Software Delivery
What does it actually take to build a successful Internal Developer Platform?
-
Designing for Defense: Architecting APIs with Zero Trust Principles
API security has moved from optional to a primary front in our system defense.
-
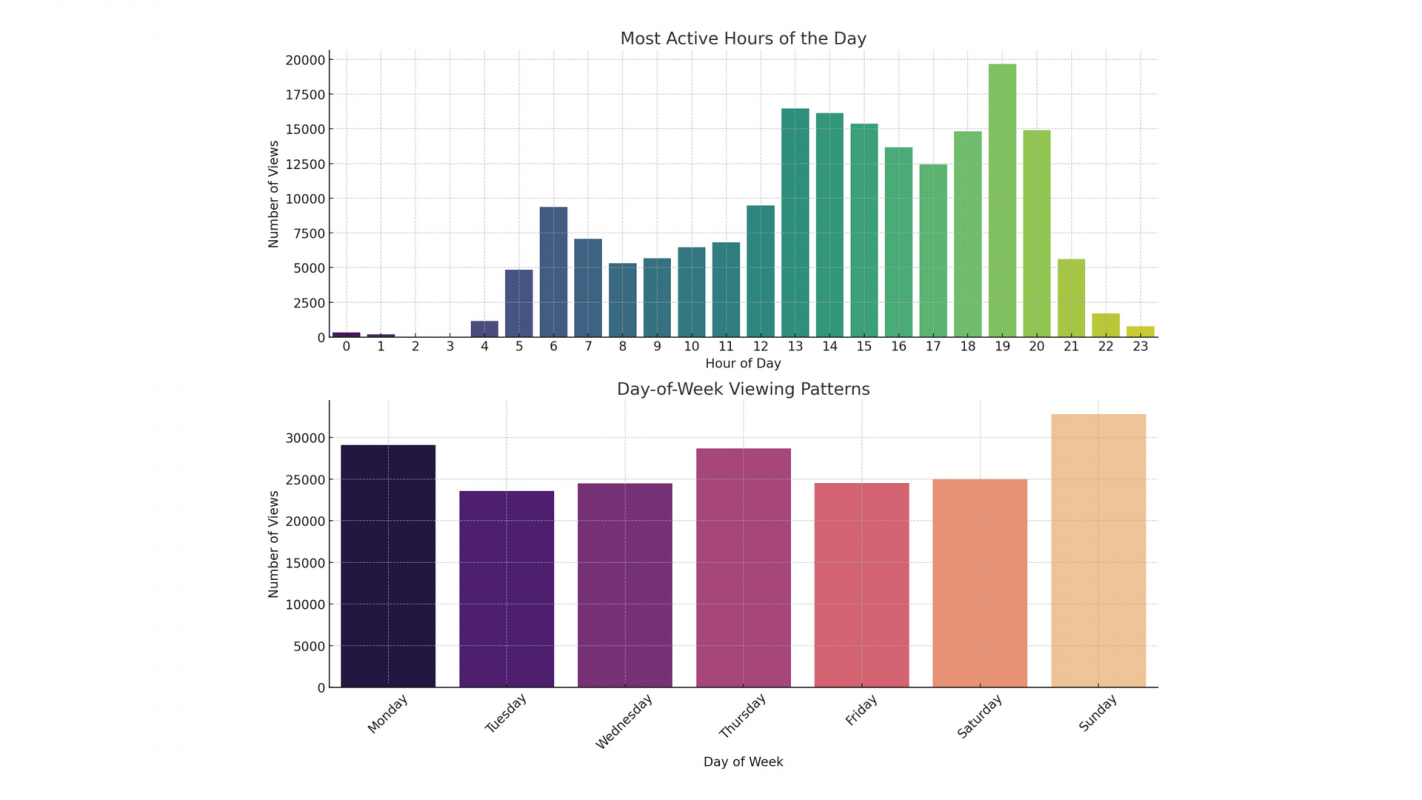
You Know What About Me? Decoding My Digital Trail Across Major Platforms
Under European rules, users can request personal data from platforms, but few do, and results are often hard to use. I accessed and parsed data from TikTok, Amazon, Google, and Instagram, uncovering surprising insights and useful tips. Find out what these platforms know about me. And maybe you too!