Tag: aws
-

Amazon S3 Around the World in 15 Buckets #DataPopkorn 2025
Let’s play a replication game on the cloud with Amazon S3. In this short talk, we will follow an S3 object on a 16-replication journey around the world, encountering surprising challenges, and learning one thing or two.
-

-
Around the World in 15 Buckets
Today, we’ll embark on a little journey around the world using S3. We’ll copy various objects across AWS regions worldwide, aiming to answer two simple questions: Does the storage class affect the speed? How does the size of the object influence the transfer time?
-
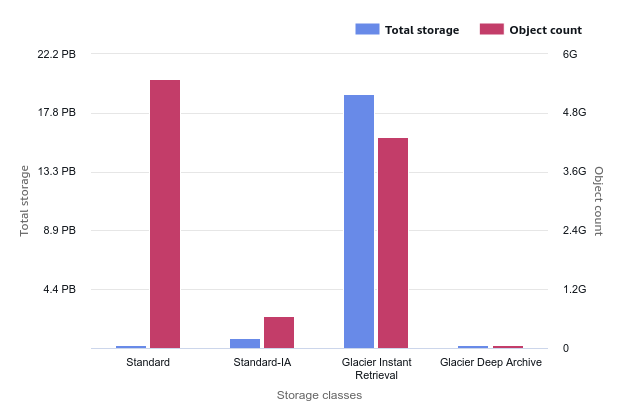
S3 Lifecycle or Intelligent-Tiering? Object Size Always Matters
Whenever you develop your logic with Lifecycle Rules or you delegate the logic to the S3 Intelligent-Tiering class, the average size of your objects on S3 is a significant factor in your storage costs.
-

WeAreDevelopers World Congress 2024 – Berlin
Watch Your Wallet and Reduce Your Carbon Footprint: A Guide to Cloud Cost Optimization.
-

Berlin AWS User Group – February 2024
Home sweet home. Last night, I relished being back at the Berlin AWS User Group, engaging in discussions about the benefits and challenges of running relational databases on AWS. The title and abstract of my presentation are provided below.
