Tag: aws
-

Looking Back at Cloud Day 2023
Almost one month has passed since Cloud Day 2023 in Milan, and it feels like yesterday.
-

Unconventional Journey With Amazon RDS
The times when a web application could only choose RDS for MySQL as a relational database on AWS are long gone. Numerous engines and deployment options for RDS, Aurora, and serverless options are just the appetizer.
-

AWS Community Day Hungary 2023 (video)
An Unconventional Journey with Amazon RDS: the video of my presentation at the AWS Community Day Hungary 2023 is now live!
-
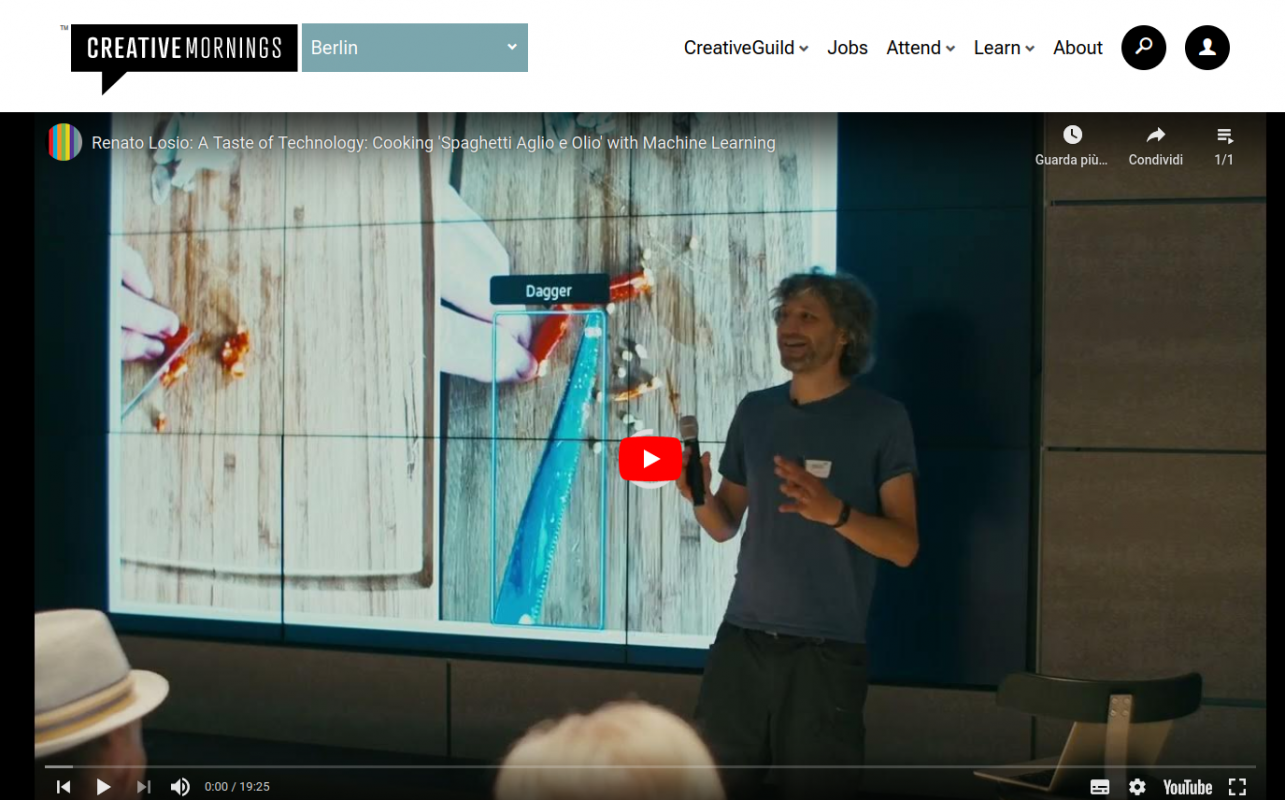
A Taste of Technology
A couple of months ago, I decided to get out of my comfort zone and accepted to give a talk at a creative community, CreativeMornings Berlin. I hope the audience enjoyed the experience as much as I did, I learned a lot and had many inspiring conversations.
-

AWS Community Day Hungary 2023
My very first virtual event for this autumn will be the AWS Community Day Hungary 2023 on October 6th. Thanks to Madhu Kumar for the opportunity to discuss my journey on AWS, as well as some benefits and drawbacks of Amazon RDS.
-

Amazon Aurora is Now 60 Times Faster than RDS for MySQL. Really.
Unlike traditional benchmarks that are lengthy and complex, this evaluation will be concise, comprising only about 200 words and taking just a couple of minutes to review the results.
