Tag: cloudwatch
-
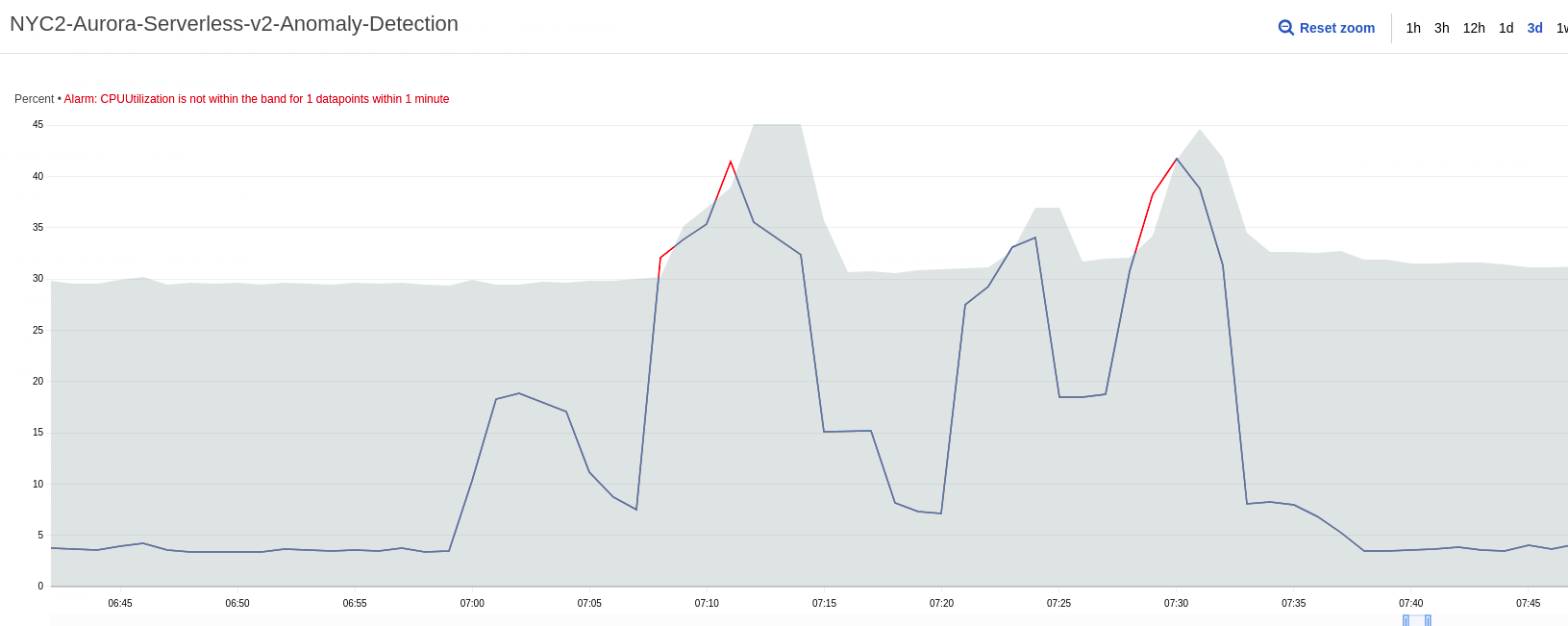
Dice, Skylines and CloudWatch Anomaly Detection
I am a lazy cloud architect with a background in site reliability engineering. That’s why I immediately felt in love with the idea behind CloudWatch Anomaly Detection when it was announced almost three years ago. Read the full article.
-
How to increase RDS storage automatically
As for today, Amazon Aurora is the only RDS database that does not require to provision a fixed storage, itRead the full article.