Tag: italiano
-

Amazon Athena Supporta Apache Spark
Amazon Athena supporta ora il sistema di elaborazione distribuito open-source Apache Spark per eseguire carichi di lavoro di analisi veloci.
-

Amazon CloudFront Supporta HTTP/3
AWS ha recentemente annunciato che le distribuzioni CloudFront supportano richieste HTTP versione 3 (HTTP/3) su QUIC. L’utilizzo di HTTP/3 è opzionale ma fornisce tempi di risposta più rapidi e maggiore sicurezza rispetto alle versioni HTTP precedenti.
-

Amazon Redshift Serverless è GA
Amazon ha recentemente annunciato la GA di Redshift Serverless, un’opzione elastica per scalare data warehouse. Il nuovo servizio consente a sviluppatori e data analyists di svolgere analisi senza preoccuparsi del provisioning e della gestione dei cluster di data warehouse.
-

Amazon annuncia le istanze EC2 Mac M1 per sviluppare e testare applicazioni su macOS
AWS ha recentemente annunciato la disponibilità delle istanze Mac M1 basate sul processore ARM Apple e progettate per CI/CD di applicazioni su piattaforma macOS. L’opzione M1 Mac è più veloce ed economica della versione Mac esistente su x86, ma richiede comunque un pagamento minimo di 24 ore.
-

TLS 1.2 diventa il minimo protocollo TLS su AWS
AWS ha recentemente annunciato che TLS 1.2 diventerà il livello minimo per gli endpoint API. Il provider cloud rimuoverà la compatibilità e il supporto per le versioni 1.0 e 1.1 su tutte le API e le region entro giugno 2023.
-
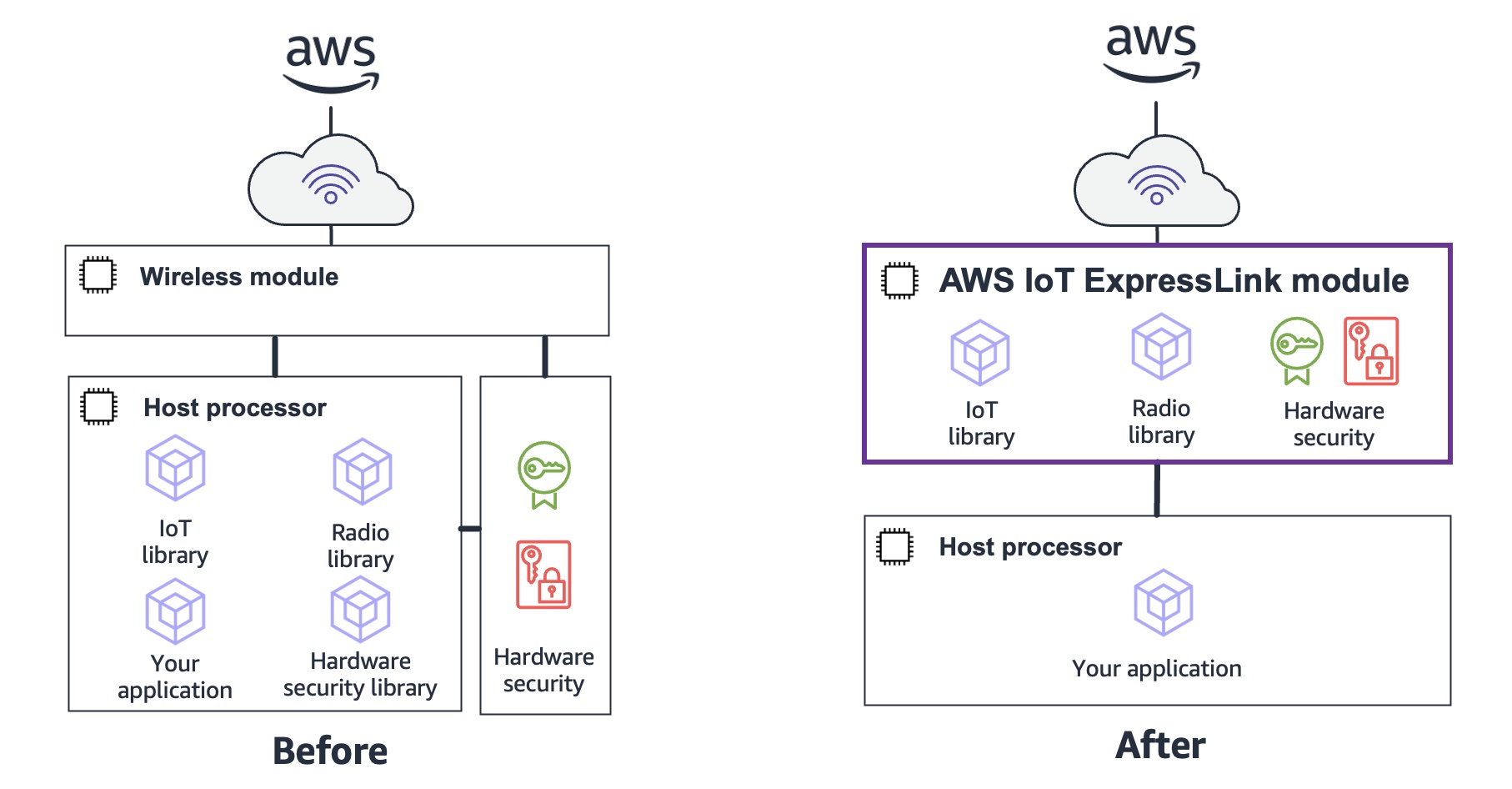
Il software per moduli hardware AWS IoT ExpressLink è GA
Amazon ha recentemente annunciato la GA di AWS IoT ExpressLink. Il software di connettività supporta moduli hardware wireless per creare soluzioni IoT connesse ai servizi AWS.
-

Cockroach Labs 2022 Cloud Report: AMD meglio di Intel?
Cockroach Labs ha recentemente pubblicato il rapporto annuale sul cloud che valuta le prestazioni di AWS, Microsoft Azure e Google Cloud per carichi di lavoro OLTP. Diversamente dal 2021, il report quest’anno non indica un cloud provider migliore, ma osserva come le istanze AMD più recenti offrono prestazioni migliori di quelle Intel. Le istanze ARM…